Liens
Astuces

|
-- Commentaire
/* Commentaire */
-- variable
declare @maVariable char(10);
set @maVariable = 'ABCDE';
declare @maVariable char(10) = 'ABCDE'; -- en une ligne
-- print
print 'Texte ' + @maVariable + ' Texte ' + cast(@intVariable as nvarchar)
-- échapper un single quote
'it doesn''t work'
-- retour à la ligne CR LF
'première ligne' + char(13) + char(10) + 'deuxième ligne'
|
like
Mot clé permettant de faire une comparaison sur un modèle plutôt que sur une valeur exacte.
|
|
select * from MaTable
where maColonne like '%BC%'
-- toutes les valeurs qui contiennent BC
|
| _ |
1 caractère
|
| % |
plusieurs caractères
|
[abc]
[a-z] |
1 caractère dans la liste ou l’intervalle
|
[^abc]
[^a-z] |
1 caractère en dehors de la liste ou de l’intervalle
|
 |
Pour utiliser _ % [ ^ comme caractère il faut les encadrer de [ ] |
Replace COUNT by EXISTS
|
|
IF((SELECT COUNT(*) FROM MyTable) > 0)
IF EXISTS (SELECT 1 FROM MyTable)
IF((SELECT COUNT(*) FROM MyTable) = 0)
IF NOT EXISTS (SELECT 1 FROM MyTable)
|
Ordre d'évaluation des clauses - binding order
- FROM
- ON
- JOIN
- WHERE
- GROUP BY
- WITH CUBE
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- TOP
Ainsi un alias de table définit dans FROM pourra être utilisé dans SELECT.
Un alias de colonne définit dans SELECT ne pourra être utilisé dans WHERE mais pourra être utilisé dans ORDER BY.
Bases de données
|
|
create database [MyDb]
drop database [MyDb]
-- Fatal error 615 occurred, avec SQL Server Express
ALTER DATABASE [MyDb] SET AUTO_CLOSE OFF
-- lister les BdD
SELECT * from sys.databases;
SELECT name,suser_sname(owner_sid) as 'owner' from sys.databases WHERE name NOT IN ('master', 'tempdb', 'model', 'msdb');
-- avec show
show databases;
|
Tables
Lister les tables
|
|
-- Lister les tables de la BdD sélectionnée
show tables;
-- Lister les tables de la BdD MaBdD
show tables from MaBdD;
select table_name
from information_schema.tables
where table_type = 'base table'
and table_name like '%xxx%';
|
Créer / supprimer une table
|
|
IF NOT EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'schema'
AND TABLE_NAME = 'MyTable')
BEGIN
create table schema.MyTable (
-- clé primaire
Id int identity(1,1) not null constraint PK_MyTable primary key,
Name varchar(50) not null,
-- insère la date courante si rien n’est spécifié
Date datetime not null default getdate()
);
END
-- Supprimer une table
drop table schema.MaTable;
-- Supprimer toutes les tables
EXEC sp_MSForEachTable 'ALTER TABLE ? NOCHECK CONSTRAINT all'
EXEC sp_MSForEachTable 'DROP TABLE ?'
|
Ajouter une colonne
|
|
IF NOT EXISTS( SELECT *
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'ma_table'
AND TABLE_SCHEMA = 'mon_schema'
AND COLUMN_NAME = 'ma_colonne')
BEGIN
ALTER TABLE [mon_schema].[ma_table]
ADD ma_colonne varchar(20),
MyColumn INT NOT NULL CONSTRAINT DF_MyTable_MyColumn DEFAULT (0);
END
|
Modifier une colonne
|
|
ALTER TABLE mon_schema.ma_table
ALTER COLUMN ma_colonne DECIMAL(18, 14)
|
 |
Management Studio (SSMS) interdit par défaut les changements qui requiert la recréation de la table.
Tools → Options → Designer → Prevent saving changes that require table re-creation |
Supprimer une colonne
|
|
ALTER TABLE MyTable
DROP COLUMN MyColumn;
-- drop the column constraint first
ALTER TABLE MyTable
DROP CONSTRAINT [DF_MyTable_MyColumn]
|
Contraintes d'intégrités
|
|
-- ajout
alter table MaTable
add constraint ck_maColonne check (maColonne>0));
-- supression
alter table MaTable
drop constraint ck_maColonne;
|
Foreign Key
C'est une contrainte permettant de lier une colonne à une clé primaire d 'une autre table.
Dans l'exemple suivant les commandes sont adressées à des clients. Pour être sur que ces clients existent bel et bien, on ajoute une contrainte sur la colonne Client_ID de la table COMMANDE afin de celle-ci ne puisse contenir que des Client_ID de la table CLIENT.
|
|
create table MyTable (
Id int identity(1,1) not null constraint PK_MyTable primary key,
OtherTable_Id int not null,
foreign key (OtherTable_Id) references OtherTable(Id)
);
alter table MyTable
add constraint FK_MyTable_OtherTable
foreign key (OtherTable_Id) references OtherTable(Id);
|
Table CLIENT
| Colonne |
Caractéristique
|
| ID |
Primary Key
|
| Nom
|
|
Table COMMANDE
| Colonne |
Caractéristique
|
| Commande_ID |
Primary Key
|
| Client_ID |
Foreign Key
|
| Quantité
|
|
|
|
-- Suppression d'une clé étrangère
ALTER TABLE COMMANDE
DROP CONSTRAINT FK_COMMANDE_CLIENT
-- Vérifier que la contrainte existe
SELECT * FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS
-- Lister les FK d'une table
SELECT
OBJECT_NAME(parent_object_id) AS [FK Table],
name AS [Foreign Key],
OBJECT_NAME(referenced_object_id) AS [PK Table]
FROM sys.foreign_keys
WHERE parent_object_id = OBJECT_ID('schema.Table');
|
|
|
-- clustered index
CREATE CLUSTERED INDEX IX_table1_column1 ON database1.schema1.table1 (column1);
-- nonclustered index
CREATE INDEX IX_table1_column1 ON table1 (column1);
-- nonclustered index avec une contrainte unique sur 3 colonnes en spécifiant leur ordre de trie
CREATE UNIQUE INDEX IX_table1_column1_column2_column3 ON table1 (column1 DESC, column2 ASC, column3 DESC);
-- drop index
DROP INDEX IX_table1_column1 ON table1
-- test si index existe déjà
IF EXISTS (SELECT name FROM sys.indexes
WHERE name = N'IX_table1_column1')
DROP INDEX IX_table1_column1 ON table1;
GO
CREATE NONCLUSTERED INDEX IX_table1_column1
ON table1 (column1);
GO
|
Données
Vider une table
|
|
-- truncate vide la table, c'est le plus rapide, pas de rollback possible
truncate table Ma_Table;
-- delete supprime toutes les lignes une par une
delete from Ma_Table;
|
|
|
INSERT INTO [mon_schema].[ma_table]
([colonne_1] ,[colonne_2]) /* optionnel, utile si les valeurs ne sont pas dans le même ordre que les colonnes */
VALUES
(N'valeur_1' ,N'valeur_2'),
(N'valeur_11' ,N'valeur_12'); /* insérer une 2ème ligne */
/* test si l'enregistrement de la ligne a déjà étét fait */
IF NOT EXISTS( SELECT *
FROM [mon_schema].[ma_table]
WHERE [colonne_1] = N'valeur_1')
BEGIN
...
END
GO
|
|
|
-- ne plus vérifier la contrainte (foreign key) lors de l'insertion de données
ALTER TABLE [MaTable] NOCHECK CONSTRAINT [FK_AutreTable_AutreColonne_Colonne1];
-- réactiver la vérification de la contrainte (foreign key) lors de l'insertion de données
ALTER TABLE [MaTable] CHECK CONSTRAINT [FK_AutreTable_AutreColonne_Colonne1];
|
Ajouter des données provenant d’une autre table
|
|
-- insert into MyTable (col1, col2) data from AnotherTable (colX, 1)
INSERT INTO schema.MyTable (col1, col2)
SELECT colX, 1 FROM schema.AnotherTable;
/* test si SELECT renvoie au moins une valeur, dans le cas contraire génère une erreur */
if @@ROWCOUNT=0
THROW 50001, 'ERREUR', 1;
|
THROW
@@ROWCOUNT
UPDATE: modifier les valeurs des lignes
|
|
-- set values based on conditions
update [table]
set [colonne1] = 'valeur',
[colonne2] = 'valeur'
where [colonne3] = 0
-- set values based on a join
update alias1
set [column1] = 'valeur'
from [table1] as alias1
inner join [table2] as alias2
on alias2.columnA = alias1.column2
|
|
|
update MATABLE
set MACOLONNE = 'valeur'
where condition
if @@ROWCOUNT=0
insert into MATABLE (MACOLONNE) values ('valeur')
|
|
update ... if @@ROWCOUNT fait un seul table/index scan
IF EXISTS (SELECT ...) UPDATE ... ELSE INSERT fait deux table/index scans, un pour le select et un pour l'update |
DELETE: supprimer des lignes
|
|
delete from TABLE
where Id = 1 or Id = 2
|
Copie d’une table vers une autre (perte des clés)
|
|
select * into NEW_TABLE
from ORIGIN_TABLE
where 1 = 0 /* empèche la copie des données de la table */
|
Chaînes de caractères
| Type
|
Description
|
| char(n) |
longueur n. 1 < n < 8000 bytes.
|
| varchar(n|max) |
longueur variable. 1 < n < 8000 bytes. max = 2^31 bytes (2Gio)
|
| nchar(n) |
unicode, longueur n. 1 < n < 4000 bytes.
|
| nvarchar(n|max) |
unicode, longueur variable. 1 < n < 8000 bytes. max = 2^31 bytes (2Gio)
|
| sysname |
nvarchar(128), valeurs NULL interdites
|
- Use char when the sizes of the column data entries are consistent.
- Use varchar when the sizes of the column data entries vary considerably.
- Use varchar(max) when the sizes of the column data entries vary considerably, and the size might exceed 8000 bytes.
Numériques exacts
| Type
|
Description
|
decimal(p,d)
numeric(p,d)
|
numérique de précision p (nb total de chiffres) avec d décimaux. 1 < p < 38 et 1 < d < p. [-10^38 to 10^38-1]
Ex: decimal(8,3) → [-99999,999 to +99999,999]
|
| int |
entier stocké sur 4 octets. [-2^31 to 2^31-1]
|
| bigint |
entier stocké sur 8 octets. [-2^63 to 2^63-1]
|
| smallint |
entier stocké sur 2 octets. [-2^15 to 2^15-1]
|
| tinyint |
entier stocké sur 1 octets. [0 to 255]
|
| money |
valeur monétaire sur 8 octets
|
| smallmoney |
valeur monétaire sur 4 octets
|
| bit |
entier de valeur 0 (FALSE), 1 (TRUE) ou NULL
|
Numériques approchés
| Type
|
Description
|
| float(n)
|
1 < n < 53. [-1.79E+308 to -2.23E-308 , 0 , 2.23E-308 to 1.79E+308]
|
| real |
float(24) sur 4 octets. [-3.40E+38 to -1.18E-38 , 0 , 1.18E-38 to 3.40E+38]
|
Date
| Type
|
Description
|
| datetime |
date + heure. 01/01/1753 - 31/12/9999. Précision de 3.33 millisecondes
|
| datetime2 |
date + heure. 01/01/0001 - 31/12/9999. Précision de 100 nanosecondes
|
| datetimeoffset |
date + heure UTC. 01/01/0001 - 31/12/9999. Précision de 100 nanosecondes
|
| smalldatetime |
date + heure. 01/01/1900 - 06/06/2079. Précision de 1 minute
|
| date |
date. 01/01/0001 - 31/12/9999
|
| time |
heure. Précision de 100 nanosecondes
|
EOMONTH
|
|
-- the current database system timestamp as a datetime value without the database time zone offset
GETDATE()
-- convert datetime to date
CONVERT(DATE, GETDATE())
-- obtenir le premier jour du mois courant
-- date courante - 1 mois, puis dernier jour du mois, puis on ajoute 1 jour
DECLARE @first_day_of_month smalldatetime = DATEADD(DAY,1,EOMONTH(GETDATE(), -1))
-- autre méthode
DECLARE @first_day_of_month smalldatetime = DATEFROMPARTS(YEAR(@today), MONTH(@today), 1)
|
Données binaires
| Type
|
Description
|
| binary(n) |
longueur fixe de n octets. 1 < n < 8000
|
| varbinary(n|max) |
longueur variable de n octets. 1 < n < 8000. max = 2^31 = 2 Gio
|
Autres
SELECT
|
|
SELECT mt.col1 AS c1 -- column alias
, 'txt' AS c2 -- static value
FROM MyTable AS mt -- table alias
WHERE (
mt.col1 > 0
AND mt.col1 < 100
)
OR mt.col1 = - 1
|
DISTINCT
Retire les doublons (duplicates) du résultat.
|
|
SELECT DISTINCT mt1.col1 AS c1
FROM MyTable1 AS mt1
WHERE mt1.col2 > 0
|
Sélection des lignes
|
|
-- Sélection des 10 premières lignes
SELECT TOP 10 *
FROM MyTable
ORDER BY Id;
-- Sélection de 50% des premières lignes
SELECT TOP 50 PERCENT *
FROM MyTable
ORDER BY Id;
-- Sélection des 10 dernières lignes
SELECT TOP 10 *
FROM MyTable
ORDER BY Id DESC;
-- Sélection de la ligne numéro N (paging)
SELECT *
FROM MyTable
ORDER BY Id
OFFSET N-1 ROWS
FETCH NEXT 1 ROWS ONLY
|
An inner query defined in the FROM clause of an outer query.
The scope of a derived table is the duration of the outer query.
|
There is probably a better way to get the same result. |
|
|
-- outer query to get the users belonging to at least 2 groups
SELECT Name, NumberOfGroups
FROM
(
-- derived table: get the number of groups a user belongs to
SELECT Name, COUNT(*) AS NumberOfGroups
FROM Users
GROUP BY UserId
) AS NumberOfGroupsPerUser
WHERE NumberOfGroups > 1
|
Group
| Id
|
Name
|
| 1 |
G1
|
| 2 |
G2
|
| 3 |
G3
|
User
| Id
|
Name
|
Group_Id
|
| 1 |
U1 |
1
|
| 2 |
U2 |
2
|
| 3 |
U3 |
null
|
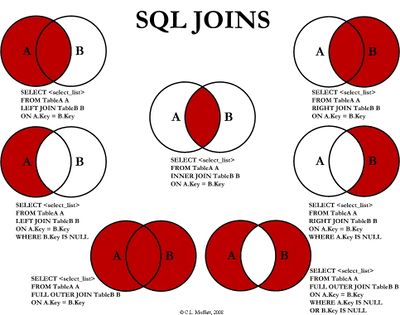
Liaison entre deux tables basée sur une égalité.
Retourne les paires des lignes qui correspondent à la jointure.
|
|
select u.Name as 'user', g.Name as 'group'
from [User] as u
join [Group] as g
on u.Group_Id = g.Id;
|
Retourne les paires des lignes qui correspondent à la jointure:
| left |
plus toutes les lignes de la table de gauche qui n'ont pas de lien dans la table de droite
|
| right |
plus toutes les lignes de la table de droite qui n'ont pas de lien dans la table de gauche
|
| full |
plus toutes les autres lignes des 2 tables qui ne correspondent pas à la jointure
|
|
|
select u.Name as 'user', g.Name as 'group'
from [User] as u
left/right/full join [Group] as g
on u.Group_Id = g.Id;
|
left
| user
|
group
|
| U1 |
G1
|
| U2 |
G2
|
| U3 |
null
|
right
| user
|
group
|
| U1 |
G1
|
| U2 |
G2
|
| null |
G3
|
full
| user
|
group
|
| U1 |
G1
|
| U2 |
G2
|
| U3 |
null
|
| null |
G3
|
LEFT JOIN / IS NULL vs NOT EXISTS
NOT EXISTS is faster because it stops its execution as soon as a record matches the criteria whereas LEFT JOIN always joins all the records.
|
|
-- fetch the groups without users
select g.Id
from Group g
left join User u
on u.GroupId = g.Id
where u.GroupId is null
-- same result with "not exists"
select g.Id
from Group g
where not exists
(
select 1
from User u
where u.GroupId = g.Id
)
|
Cross join
Produit cartésien (cross-product) de 2 tables.
|
|
select u.Name as 'user', g.Name as 'group'
from [User] as u
cross join [Group] as g;
|
| user
|
group
|
| U1 |
G1
|
| U2 |
G1
|
| U3 |
G1
|
| U1 |
G2
|
| U2 |
G2
|
| U3 |
G2
|
| U1 |
G3
|
| U2 |
G3
|
| U3 |
G3
|
Operators
Concaténation des résultats de 2 requêtes. Les doublons sont supprimés.
union all permet de conserver les doublons.
|
|
select Name from [User]
union
select Name from [Group];
|
Intersect - Except
|
|
SELECT col1, col2
FROM MyTable1
EXCEPT
SELECT col1, col2
FROM MyTable2
|
Cross Apply permet de faire une jointure interne entre une table et une table-valued fonction (fonction qui retourne une table).
Ce qui revient à exécuter une TVF pour chaque ligne d'une table.
Outer Apply permet de faire une jointure externe sur le même principe.
|
|
-- pour chaque personne, appel de la tvf ufnGetContactInformation qui va ajouter des colonnes au résultat
SELECT *
FROM Person.Person AS p
CROSS APPLY dbo.ufnGetContactInformation(p.Id)
|
Permet de mettre à jour la table Destination avec les éléments de la table Source.
|
|
merge [Destination Table] as target
using [Source Table] as source
on target.id = source.id
when matched and target.field1 = source.field1 then
delete
when match then
update set
field1 = source.field1,
field2 = source.field2
when not matched then
insert (id, field1, field2)
values (source.id, source.field1, source.field2);
|
Colonnes calculées
|
|
select Salaire, Commission,
round(Salaire*1.1, 0) as SalairePlusDixPourcent,
-- on utilise coalesce pour remplacer les Commission null par 0
Salaire + coalesce(Commission,0) as SalairePlusCommission
from Employés
|
Référencer une colonne calculée
order by
|
|
-- seul order by permet de référencer un alias
select Salaire, Commission, round(Salaire*1.1, 0) as SalairePlusDixPourcent
from Employés
order by SalairePlusDixPourcent
|
Sous-requête
|
|
select Salaire, Commission, SalairePlusDixPourcent, SalairePlusCommission, sum(SalairePlusCommission) over() as Somme from
(
select Salaire, Commission,
round(Salaire*1.1, 0) as SalairePlusDixPourcent,
Salaire + coalesce(Commission,0) as SalairePlusCommission
from Employés
) as CalcSum
|
|
|
-- calculer la somme pour une colonne calculée
with CalcSum as
(
select Salaire, Commission,
round(Salaire*1.1, 0) as SalairePlusDixPourcent,
Salaire + coalesce(Commission,0) as SalairePlusCommission
from Employés
)
select Salaire, Commission, SalairePlusDixPourcent, SalairePlusCommission, sum(SalairePlusCommission) over() as Somme
from CalcSum
|
Opérateurs
if else
|
|
if @var = 0
print 'ok'
else
begin
print 'ko'
print 'ko multi-lignes'
end
|
|
|
select * from MaTable
where col1 in (0, 1)
-- équivalent à
where col1 = 0 or col1 = 1
-- Sous-requêtes
-- Liste les Id de tous les Manager
-- puis récupère le Nom pour chaque Id
select Id, Nom from Employés
where Id in (select Manager from Employés)
-- Liste les Id de tous les Manager
-- puis liste tous les Employés qui n'ont pas ces Id
-- attention la sous-requête ne doit pas retourner de valeurs null
select Id, Nom from Employés
where Id not in (select Manager from Employés where Manager is not null)
|
|
SELECT 1 est équivalent à SELECT * ou SELECT 0 |
|
|
-- séléctionne toutes les lignes de Table1 qui ont un Id dans Table2
SELECT * FROM Table1 AS t1
WHERE EXISTS (SELECT 1 FROM Table2 AS t2 WHERE t1.Id = t2.Id )
-- séléctionne toutes les lignes de Table1 qui n'ont un Id dans Table2
SELECT * FROM Table1 AS t1
WHERE NOT EXISTS (SELECT 1 FROM Table2 AS t2 WHERE t1.Id = t2.Id )
-- séléctionne tous clients de la table Clients qui ne sont pas dans la table BlackListedClients
select *
from Clients AS c
where not exists
(select *
from BlackListedClients as blc
where c.Id = blc.id)
-- équivalant à
select *
from Clients AS c
where c.Id not in
(select blc.id
from BlackListedClients as blc
where c.Id = blc.id)
|
|
|
declare @i int
set @i = 0
while @i < 50
begin
print @i
set @i = @i + 1
end
|
Agrège par hiérarchie de valeurs.
|
|
# groupe les éléments de colonne1 et compte leurs occurrences
# la première ligne somme toutes les occurrences → rollup
select colone1, count(colonne1) as 'Occurrence'
from MaTable
group by colonne1 with rollup
order by 'Occurrence' desc
# colonne1 | Occurrence
# NULL | 50
# 2 | 30
# 5 | 20
|
Fonctions
SUM, MIN, MAX, STRING_AGG
|
|
-- regroupe les produits par location et somme leurs quantités
SELECT LocationId, SUM(Quantity) AS QuantityByLocation, STRING_AGG(ProductId, ',')
FROM ProductInventory
GROUP BY LocationId
HAVING SUM(Quantity) > 1000 -- filtre sur le résultat de la colonne agrégée
-- somme des quantités de tous les produits
SELECT SUM(Quantity) AS TotalQuantity
FROM Production.ProductInventory
-- pour chaque produit, affiche les quantités min et max stockées dans les différentes locations
SELECT p.Name, MIN(pi.Quantity), MAX(pi.Quantity)
FROM Production.Product AS p
INNER JOIN Production.ProductInventory AS pi
ON p.ProductID = pi.ProductID
GROUP BY p.Name
|
Count
|
|
-- compte le nombre de ligne d'une table
SELECT COUNT(*)
FROM Product
-- compte le nombre d'occurences différente, ne prend pas en compte NULL
SELECT COUNT(DISTINCT Color)
FROM Product
-- pour chaque produit, compte le nombre d'étagère
SELECT p.Name, COUNT(pi.Shelf)
FROM Production.Product AS p
INNER JOIN Production.ProductInventory AS pi
ON p.ProductID = pi.ProductID
GROUP BY p.Name
HAVING COUNT(pi.Shelf) > 1 -- filtrer seulement les produits qui ont plus d'une étagère
|
Math functions
| ROUND |
arrondi
|
| RAND |
chiffre aléatoire entre 0 et 1
|
| POWER - SQRT |
puissance - racine carrée
|
| CEILING - FLOOR |
plus petit entier supérieur ou égal
plus grand entier inférieur ou égal
|
|
|
SELECT Price,
ROUND(Price, 1), -- 1 décimale
ROUND(Price, 2), -- 2 décimales
ROUND(Price, -1) -- 1 entier (123 → 120)
SELECT RAND() -- le serveur choisit un seed différent à chaque exécution
SELECT RAND(1) -- on force le seed, le chiffre généré est le même si le seed est le même
|
|
|
-- PARSE: string to date/time and number types only
SELECT PARSE('12/31/2019' AS DATE);
SELECT PARSE('31/12/2019' AS DATE USING 'fr-FR');
-- retourne NULL au lieu d'une erreur si la parse n'a pas marché
SELECT TRY_PARSE('31/12/2019' AS DATE);
-- CAST: data type to another data type
SELECT CAST(9.5 AS int);
SELECT TRY_CAST(9.5 AS decimal(6,4));
-- CONVERT: same as CAST with a style
SELECT CONVERT (DATE, '12/31/2019');
SELECT TRY_CONVERT (DATE, '31/12/2019');
-- ISNUMERIC, ISDATE
DECLARE @Var1 NVARCHAR(50) = '123'
DECLARE @Var2 NVARCHAR(50) = '01/01/1980'
SELECT ISNUMERIC (@Var1), ISNUMERIC (@Var2), ISDATE(@Var1), ISDATE(@Var2)
-- 1 0 0 1
|
CONVERT styles
Time functions
| SELECT SYSDATETIME() |
2019-04-17 14:36:21.9359144
|
| SELECT SYSDATETIMEOFFSET() |
2019-04-17 14:36:21.9359144 +02:00
|
| SELECT SYSUTCDATETIME() |
2019-04-17 12:36:21.9359144
|
| SELECT CURRENT_TIMESTAMP |
2019-04-17 14:36:21.933
|
| SELECT GETUTCDATE() |
2019-04-17 12:36:21.933
|
| SELECT GETDATE() |
2019-04-17 14:36:21.933
|
|
|
-- subpart
SELECT DAY(GETDATE()) -- 17
SELECT MONTH(GETDATE()) -- 4
SELECT YEAR(GETDATE()) -- 2019
SELECT DATEPART(d, GETDATE()) -- 17
SELECT DATEPART(m, GETDATE()) -- 4
SELECT DATEPART(yy, GETDATE()) -- 2019
SELECT DATENAME(m, GETDATE()) -- April
-- build date
SELECT DATEFROMPARTS(2019, 4, 17)
SELECT DATETIMEFROMPARTS(2019, 4, 17, 12, 0, 0, 0)
SELECT SMALLDATETIMEFROMPARTS(2019, 4, 17, 12, 0)
SELECT DATETIME2FROMPARTS(2019, 4, 17, 12, 0, 0, 0, 0)
SELECT DATETIMEOFFSETFROMPARTS(2019, 4, 17, 12, 0, 0, 0, 2, 0, 0)
SELECT TIMEFROMPARTS(12, 0, 0, 0, 0)
-- diff
SELECT DATEDIFF(yy, '1/1/2018', '1/1/2019') -- 1
SELECT DATEDIFF(m, '1/1/2018', '1/1/2019') -- 12
SELECT DATEDIFF(d, '1/1/2018', '1/1/2019') -- 365
-- modification
SELECT DATEADD(yy, 1, CONVERT(date, getdate())) -- 2020-04-17
SELECT DATEADD(m, 1, CONVERT(date, getdate())) -- 2019-05-17
SELECT DATEADD(d, 1, CONVERT(date, getdate())) -- 2019-04-18
SELECT EOMONTH(GETDATE()) -- 2019-04-30
SELECT EOMONTH(GETDATE(), 1) -- 2019-05-31
|
CHOOSE
Retourne la nième valeur.
|
|
SELECT CHOOSE(2, 'A', 'B', 'C') -- B
|
Retourne une des 2 valeurs en fonction du résultat du test.
|
|
SELECT IIF(1 = 1, 'TRUE', 'FALSE')
|
|
|
-- simple case
SELECT CASE 2
WHEN 1 THEN 'A'
WHEN 2 THEN 'B'
WHEN 3 THEN 'C'
ELSE 'Z'
END
-- search case
DECLARE @TempTable TABLE (Id INT NOT NULL PRIMARY KEY, Value NVARCHAR(50) NOT NULL);
INSERT @TempTable VALUES (1, 'A'), (2, 'B'), (3, 'C'), (4, 'D');
SELECT *,
CASE
WHEN id % 2 = 0 THEN 'Pair'
WHEN id % 2 = 1 THEN 'Impair'
ELSE 'Error'
END AS "Pair / Impair"
FROM @TempTable
|
| Id
|
Value
|
Pair / Impair
|
| 1 |
A |
Impair
|
| 2 |
B |
Pair
|
| 3 |
C |
Impair
|
| 4 |
D |
Pair
|
ISNULL
Retourne la première valeur si elle est non-nulle, sinon la deuxième. Ne prend que 2 arguments.
|
|
SELECT ISNULL('Value', 'Other') -- Value
SELECT ISNULL(NULL, 'Other') -- Other
|
Retourne la première valeur non-nulle. Prend 2 arguments ou plus.
|
|
COALESCE(NULL, NULL, 'Value1', 'Value2') -- Value1
|
|
|
DECLARE @TransactionName VARCHAR(20) = 'Transaction1';
-- start transaction
BEGIN TRAN @TransactionName;
-- update table
UPDATE [table]
SET [column1] = 1
WHERE [column2] = 1;
-- display the modifications
SELECT [column1],
[column2]
FROM [table];
-- rollback the transaction
ROLLBACK TRAN @TransactionName;
|
Stored procedure / procédure stockée
|
|
-- create / alter
CREATE PROCEDURE schema.USP_MySP
@P_MyParameter BIT NULL
AS
BEGIN
END;
-- run
DECLARE @p4 [schema].[T_IdListTable]
INSERT INTO @p4 VALUES (1)
INSERT INTO @p4 VALUES (2)
DECLARE @p5 INT = 0
EXEC [schema].[USP_MyStoredProc]
@P_One = '2019-02-12',
@P_Two = NULL,
@P_Three = DEFAULT, -- for tables
@P_Four = @p4,
@P_Five = 0;
-- rename
EXEC sp_rename 'schema.OldName', 'NewName';
|
Delete all SP
|
|
DECLARE c CURSOR FOR
SELECT [name], [schema_id] FROM sys.objects WHERE type = 'p';
OPEN c;
FETCH NEXT FROM c
INTO @spName,
@schemaName;
WHILE @@fetch_status = 0
BEGIN
SET @dropCmd = 'drop procedure [' + SCHEMA_NAME (@schemaName) + '].[' + @procName + ']';
EXEC (@dropCmd);
FETCH NEXT FROM cur
INTO @spName,
@schemaName;
END;
CLOSE c;
DEALLOCATE c;
|
Table-valued functions
|
|
DECLARE @p1 [schema].[T_IdListTable]
SELECT * FROM [schema].[FN_MyFunction](@p1, NULL, 0)
|
|
|
-- test if a TVF exists in the db
IF EXISTS (SELECT 1
FROM INFORMATION_SCHEMA.ROUTINES
WHERE SPECIFIC_SCHEMA = 'schema'
AND SPECIFIC_NAME = 'FN_MyFunction'
AND ROUTINE_TYPE = 'FUNCTION')
PRINT 'Exists'
ELSE
PRINT 'Doesn''t exist'
|
Store procedure vs function
- FN are used to filter data only, no DML(INSERT/UPDATE/DELETE) are allowed.
Cursor : boucle sur toutes les noms des tables de la BdD
|
|
DECLARE tableCursor CURSOR FOR
SELECT [name] FROM sys.Tables
WHERE [type]='U' -- Table
ORDER BY [name]
DECLARE @tableName sysname
OPEN tableCursor
-- Charge la première valeur dans tableName
FETCH NEXT FROM tableCursor INTO @tableName
WHILE (@@FETCH_STATUS <> -1)
BEGIN
print 'Table name: ' + @tableName
-- Charge la valeur suivante dans tableName
FETCH NEXT FROM tableCursor INTO @tableName
END
-- Close cursor and free memory
CLOSE tableCursor
DEALLOCATE tableCursor
|
|
Il n'est pas possible d'utiliser une variable comme nom de colonne dans un select. |
User-Defined Table Type
Programmability → Types → User-Defined Table Types
|
|
CREATE TYPE [IdListTable] AS TABLE(
[Id] [INT] NOT NULL
)
GO
-- autoriser le rôle MyDbRole à utiliser le type IdListTable
GRANT EXECUTE ON TYPE:: [IdListTable] TO [MyDbRole]
GO
-- utiliser le UDTT comme paramètre d'une SP
DECLARE @LIST AS [IdListTable];
INSERT INTO @LIST (Id)
VALUES (10), (20)
EXEC [USP_MyStoreProc]
@P_Param1 = @LIST
|
Modifier un Type
Le Type ne peut être modifier car il est utilisé ailleurs.
|
|
-- renommer le type
-- ne pas mettre le schema dans le nouveau nom
EXEC sp_rename '[schema].[T_MyTypeTable]', 'T_MyTypeTable2'
-- re-créer le type avec les modifications
CREATE TYPE [schema].[T_MyTypeTable] AS TABLE(
-- ...
)
-- générer le code de rafraîchissement (remplacer T_MyTypeTable)
SELECT '[' + s.name + '].[' + OBJECT_NAME (d.referencing_id) + ']' AS 'Name',
'EXEC sp_refreshsqlmodule ''[' + s.name + '].[' + OBJECT_NAME (d.referencing_id) + ']''' AS 'Cmd to execute'
FROM sys.sql_expression_dependencies AS d
INNER JOIN sys.objects AS o
ON d.referencing_id = o.[object_id]
INNER JOIN sys.schemas AS s
ON o.[schema_id] = s.[schema_id]
WHERE referenced_class_desc = 'TYPE'
AND referenced_entity_name = 'T_MyTypeTable';
-- exécuter le code de rafraichissement
EXEC sp_refreshsqlmodule '[schema].[FN_MyFunction]'
-- supprimer le type renommé
DROP TYPE [pri.T_MyTypeTable2]
|
Temp table
- They are created in the tempdb database
|
|
IF OBJECT_ID ('tempdb..#TempTable') IS NULL
CREATE TABLE #TempTable
(
Id INT NOT NULL PRIMARY KEY,
Value NVARCHAR(50) NOT NULL
);
ELSE
TRUNCATE TABLE #TempTable;
DROP TABLE IF EXISTS #TempTable;
-- create the TempTable and insert data from another table
SELECT *
INTO #TempTable
FROM AnotherTable;
|
Table variable
- They are created in the tempdb database
- They are only visible in the batch where they have been created
- No need to drop them, they persist as long as the session is open, just like any other variable
- They are unaffected by transactions
|
|
DECLARE @TableVar TABLE
(
Id INT NOT NULL PRIMARY KEY,
Value NVARCHAR(50) NOT NULL
);
INSERT @TableVar
VALUES (1, 'One');
-- insert lines from a query
INSERT INTO @TableVar (Id, Value)
SELECT Id, Value
FROM AnotherTable;
-- empty the table
DELETE FROM @TableVar;
|
Vue - View
Une vue est un table virtuelle, elle n'occupe pas d'espace disque pour ses données. Elle ne stocke que sa requête.
C'est l'équivalent d'une fonction sans paramètre.
|
|
IF EXISTS (SELECT *
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'mon_schema'
AND TABLE_NAME = 'ma_vue')
BEGIN
drop view mon_schema.ma_vue;
end
go
CREATE VIEW mon_schema.ma_vue
AS
SELECT *
FROM ma_table
WHERE [Colonne1] = 10
GO
|
|
create view doit être encadré par 2 instructions go |
|
Limitations:
- no outer joins
- no sub-queries
- no reference to other views
- no unions
|
|
|
-- Set the options to support indexed views.
SET NUMERIC_ROUNDABORT OFF;
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT, QUOTED_IDENTIFIER, ANSI_NULLS ON;
-- Create view with SCHEMABINDING.
IF OBJECT_ID ('pri.VW_Item', 'view') IS NOT NULL
DROP VIEW pri.VW_Item;
GO
CREATE VIEW pri.VW_Item
WITH SCHEMABINDING
AS
SELECT ItemId, Description
FROM dbo.Item;
GO
-- Create an indexes
CREATE UNIQUE CLUSTERED INDEX FK_Item_VW_Item_ItemId
ON pri.VW_Item (ItemId);
GO
CREATE INDEX IDX_UN_VW_Item_Description
ON pri.VW_FreightEntryWeightCondition (Description);
GO
|
Stocke le résultat d'une requête pour pouvoir la réutilser.
|
|
;WITH
ProductQty AS
(
SELECT ProductID, Quantity
FROM ProductInventory
)
SELECT ProductID, SUM(Quantity) AS SumQuantity
FROM ProductQty
GROUP BY ProductID
-- il n'est pas possible d'avoir une CTE dans une autre CTE
-- mais on peut déclarer une 2ème CTE qui référence la première
;WITH
Cte1 AS
(
SELECT Id, Value
FROM MyTable1
),
Cte2 As
(
SELECT Id, Value
FROM Cte1
)
SELECT Id, Value
FROM Cte2
GROUP BY ProductID
|
|
Bien penser à terminer la commande précédant la CTE avec un ; |
|
|
-- Get all the employees who does not have a manager
-- Then recursively get all their subordinates
;WITH
cte_hierarchy AS
(
SELECT EmployeeId,
Name,
ManagerId
FROM Employees
WHERE ManagerId IS NULL
UNION ALL
SELECT e.EmployeeId,
e.Name,
e.ManagerId
FROM Employees e
INNER JOIN cte_hierarchy cte
ON cte.EmployeeId = e.ManagerId
)
SELECT * FROM cte_hierarchy;
|
String
|
|
SELECT LEFT('12345', 3) -- 123
SELECT RIGHT('12345', 3) -- 345
SELECT LEN('12345 ') -- 5 ne prend pas en compte les espaces de fin de string
SELECT DATALENGTH('12345 ') -- 6
SELECT LTRIM(' abc ') -- 'abc '
SELECT RTRIM(' abc ') -- ' abc'
|
Découper une chaîne de caractères
|
|
SET @string = 'string'
SET @troisPremiersChar = LEFT(@string,3) -- str
SET @sub = SUBSTRING(@string, 2, 4) -- trin
|
Concat
|
|
-- concat le résultat d'un select sur une seule ligne
DECLARE @cmd NVARCHAR(MAX) = ''
SELECT @cmd = @cmd + N'tSQLt.FakeTable [' + tableName + N'];' FROM tableNames;
|
Autres
Variable comme nom de colonne dans un select
Comme ce n'est pas possible, une astuce est de générer du code sql avec ces noms de colonnes.
|
|
SELECT 'if exists (select 1 from Reporting.vFatcaXml where ' + Column_name + ' like ''%xxx%'')
begin
print ''' + Column_name + '''
end;'
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'MaTable'
and DATA_TYPE = 'varchar'
and table_schema = 'dbo'
-- ce qui génère pour chaque colonne varchar de MaTable
select 1 from Reporting.vFatcaXml where Colonne1 like '%xxx%')
begin
print 'Colonne1'
end;
|
|
|
THROW 50001, 'Message', 1;
/* Message avec des paramètres */
EXEC sys.sp_addmessage 50001, 16, '''%s'' is not valid', @replace='replace';
DECLARE @Message varchar(max) = FORMATMESSAGE(50001, 'paramètre'); /* marche avec les paramètres des SqlCommand C# */
THROW 50001, @Message, 1;
/* un message id ne peut être ajouté qu'une fois sinon un warning est généré
« You must specify 'REPLACE' to overwrite an existing message »
Pour éviter cela on peut ajouter « @replace='replace' » ou ne pas exécuter plus d'une fois « sp_addmessage » */
IF NOT EXISTS( SELECT * FROM sys.messages WHERE message_id = 50001)
BEGIN
EXEC sys.sp_addmessage 50001, 16, '''%s'' is not a valid'
END
|
sp_addmessage
Obtenir les clés primaires d’une table
|
|
select c.COLUMN_NAME
from INFORMATION_SCHEMA.TABLE_CONSTRAINTS pk ,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE c
where pk.TABLE_NAME = @TableName
and CONSTRAINT_TYPE = 'PRIMARY KEY'
and c.TABLE_NAME = pk.TABLE_NAME
and c.CONSTRAINT_NAME = pk.CONSTRAINT_NAME
|
Requête sur deux bases de données
|
|
select * from [base1].[dbo]._EVENTS
select * from [base2].[dbo]._EVENTS
|
Limitation sur les noms des identifiants
Les identifiants qui contiennent des caractères spéciaux (comme espace) doivent être encapsulés entre [ ]
Tous les caractères sont authorisés sauf [
Les identifiants contiennent au maximum 128 caractères.
Obtenir des infos sur un élément
|
|
sp_help 'Schema.ConstraintName'
|
charset
|
|
-- liste des types de colonnes et leurs charset
select data_type, character_set_catalog, character_set_schema, character_set_name, collation_catalog, collation_schema, collation_name, count(*) count
from information_schema.columns
group by data_type, character_set_catalog, character_set_schema, character_set_name, collation_catalog, collation_schema, collation_name;
-- le charset et la collation d'une colonne
select character_set_name, collation_name
from information_schema.columns
where TABLE_SCHEMA = 'xxx' and TABLE_NAME = 'yyy' and COLUMN_NAME = 'zzz'
|
|
iso_1 → ISO 8859-1
UNICODE → UCS-2 |
Générer toutes les combinaisons
|
|
-- table temporaire pour stocker l'ensemble des valeurs possibles
declare @table_temp table (i tinyint)
-- compteur, initialisé à 1
declare @i tinyint
set @i = 1
-- on définit la valeur max pour l'ensemble des valeurs possibles
while @i < 6
begin
-- on remplit la table temporaire avec l'ensemble des valeurs possibles
insert into @table_temp values (@i)
set @i = @i + 1
end;
/* @table_temp
i
-
1
2
3
4
5
*/
with
w1 as (
SELECT t1.i as i1, t2.i as i2
FROM @table_temp t1
cross join @table_temp t2
where t1.i < t2.i)
SELECT w1.*, t1.i as i3
FROM @table_temp t1
cross join w1
where w1.i2 < t1.i
/* Résultat: combinaison de 3 éléments parmi (1,2,3,4,5)
1 2 3
1 2 4
1 2 5
1 3 4
1 3 5
1 4 5
2 3 4
2 3 5
2 4 5
3 4 5
*/
|
Stocker la première ligne d'un select dans une variable
|
|
DECLARE @MyVar nvarchar(50)
SELECT TOP 1 @MyVar = Col1
FROM MyTable
|
Lister les tables dans lesquelles un clé primaire est utilisée comme clé étrangère
|
|
SELECT objs1.name AS ConstraintName,
objs2.name AS FromTable,
objs3.name AS ToTable
FROM sys.foreign_key_columns fkcols
INNER JOIN sys.objects objs1
ON objs1.object_id = fkcols.constraint_object_id -- ID de la contrainte FOREIGN KEY.
INNER JOIN sys.objects objs2
ON objs2.object_id = fkcols.parent_object_id -- ID du parent de la contrainte, qui est l'objet référençant.
INNER JOIN sys.objects objs3
ON objs3.object_id = fkcols.referenced_object_id -- ID de l'objet référencé, qui contient la clé candidate.
WHERE objs3.name = 'AmountCalculationMethod';
|
Erreurs
Cannot insert explicit value for identity column when IDENTITY_INSERT is set to OFF
Les champs identity sont auto générés. Pour pouvoir y forcer une valeur il faut activer IDENTITY_INSERT.
|
|
SET IDENTITY_INSERT MaTable ON
INSERT MaTable (Id) VALUES (1)
SET IDENTITY_INSERT MaTable OFF
|
